
Guarding the Future: Navigating the Maze of Adversarial AI Attacks
Adversarial machine learning (AML) attacks pose a significant risk to AI systems, which are becoming increasingly integral to both our businesses and daily lives. These attacks can degrade AI performance, produce incorrect results, lead to data breaches, and cause various security problems. Understanding the nature of AML attacks and developing effective countermeasures is crucial for anyone involved in AI system protection.
A brief introduction to the report
The NIST AI 100-2e2023 report, titled “Adversarial Machine Learning – A Taxonomy and Terminology of Attacks and Mitigations,” provides a detailed categorization and terminology for adversarial machine learning attacks and their mitigation strategies. It is an invaluable resource for those seeking to comprehend the AML landscape and gain a broad yet detailed understanding of both the attacks and their counteractions.
I appreciate how the report organizes AML attacks and mitigations. It classifies AI technologies into two main categories: Predictive AI and Generative AI. Within each category, attacks are organized based on the attacker’s goals, the capabilities needed to achieve these objectives, and the specific types of attacks that fit these categories.
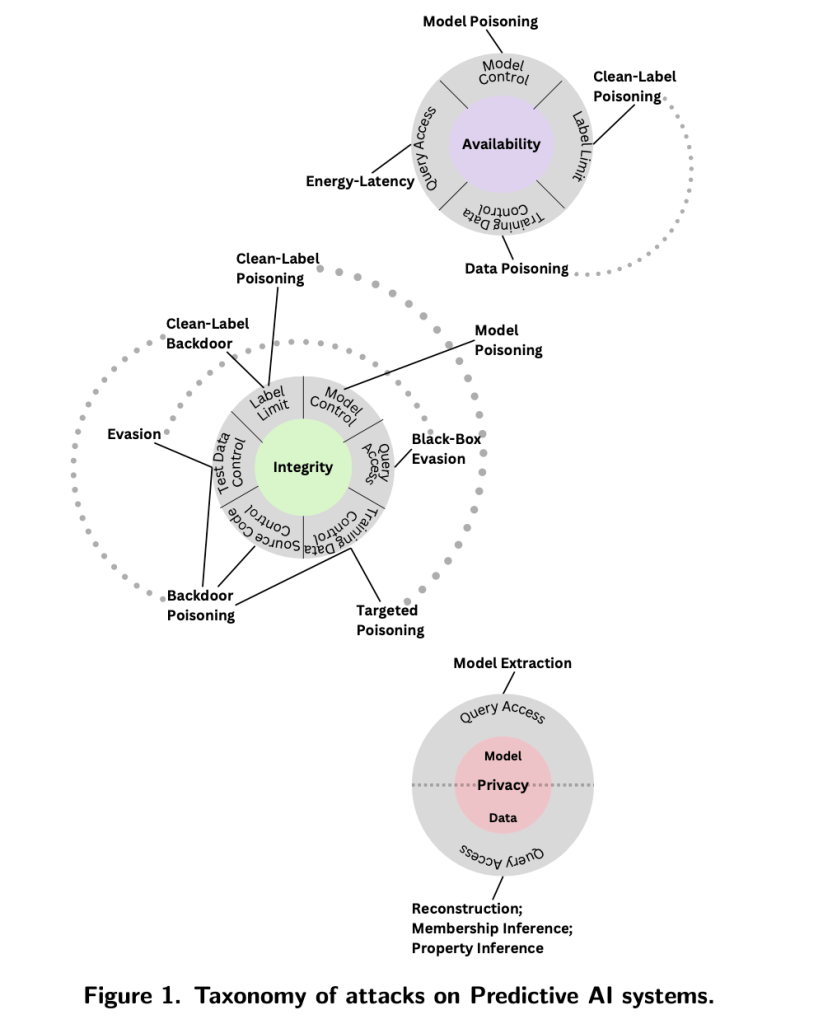
For instance, the report illustrates that attacks against Predictive AI target three main objectives: Availability breakdown, Integrity violations, and Privacy compromise. The classification proceeds to identify the capabilities needed for these attacks, such as Model Control and Training Data Control, and then details the specific attack types corresponding to these capabilities. This structure offers a clear perspective on the goals, capabilities, and attack types an adversary might employ.
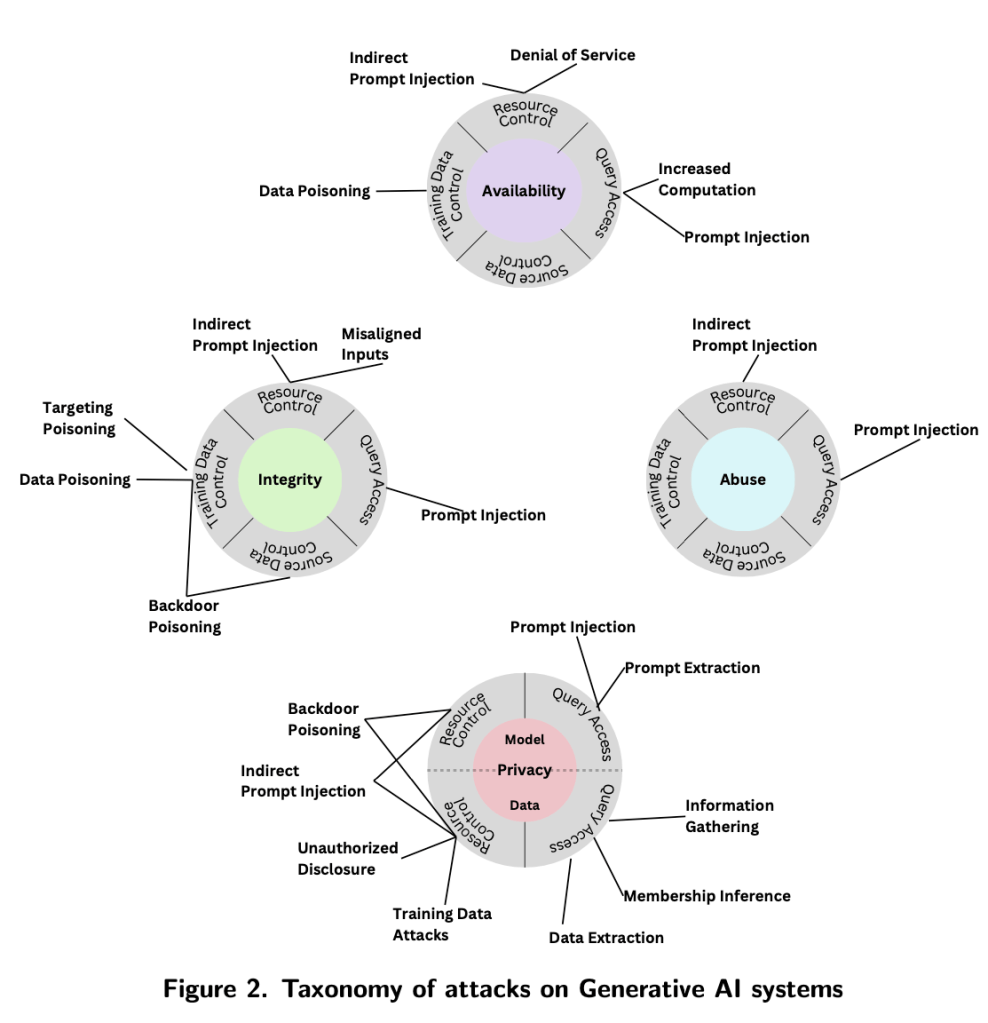
For Generative AI, the report introduces an additional category, “Abuse,” which is not found in Predictive AI. In this context, “abuse” refers to scenarios where attackers misuse a GenAI system for harmful objectives, such as spreading hate speech, generating inflammatory media, or facilitating cyberattacks. This addition is both relevant and necessary, highlighting the distinct threats that Generative AI faces.
Key content about Predicative AI
For Predictive AI, the report introduces the following attack types:
The document outlines a taxonomy of adversarial machine learning attacks against Predictive AI (PredAI) systems, identifying major attack types based on the attacker’s objectives: Availability breakdown, Integrity violations, and Privacy compromise. The attacks are further classified based on the capabilities required to execute them. Major attack types against PredAI systems include:
Organized by the attacker’s goal, the major attack types against Predictive AI (PredAI) systems are:
1. Availability Breakdown:
- Model poisoning: Manipulating the AI model to degrade its performance or functionality.
- Clean-label poisoning:Utilizing correctly labeled data in a malicious way to compromise the model’s integrity.
- Data Poisoning: Altering the training data to corrupt the model’s training process and integrity.
- Energy-Latency Attacks: Exploiting the energy consumption and latency aspects of the system to hamper its availability.
2. Integrity Violations:
- Clean-Label Poisoning: Utilizing correctly labeled data in a malicious way to compromise the model’s integrity.
- Model Poisoning: Model poisoning directly modifies the trained ML model to inject malicious functionality .
- Black-box Evasion: Manipulating the model’s input to produce incorrect outputs without knowledge of the model’s internal structure.
- White-box Evasion Attacks: Evading the correct functioning of the AI system to produce incorrect outcomes.
- Backdoor Poisoning: Inserting hidden malicious functionality or backdoors that can be triggered under certain conditions.
- Targeted Poisoning: Focused attacks aiming to specifically alter the model’s output under particular scenarios.
3. Privacy Compromise:
- Model Extraction: Extracting the model’s parameters or architecture to replicate or reverse-engineer the model.
- Data Reconstruction: Data reconstruction attacks aim to recover individual data from released aggregate information.
- Membership Inference: Attempts infer whether a particular data point was part of the training dataset, compromising data privacy .
- Property Inference: Inferring properties of the training data, such as the distribution of the data, from the model’s output.
Mitigations:
Evasion attack:
- Adversarial Training: training the model with adversarial examples to improve its robustness against evasion attacks.
- Randomized smoothing: Adding noise to the model’s output to make it more robust against evasion attacks.
- Formal verification: Using formal verification to prove the robustness of the model against evasion attacks.
Poisoning attack:
- Training data sanitization: Sanitizing the training data to remove any malicious data points.
- Trigger reconstruction: Reconstruct the backdoor trigger and remove it from the model.
- Model inspection and sanitization: Analyze the trained model to identify and remove any malicious functionality before deployment.
Model Poisoning:
- Model inspection and sanitization: Analyze the trained model to identify and remove any malicious functionality before deployment.
Privacy Attacks:
- Differential privacy: Adding noise to the model’s output to protect the privacy of the training data.
The following table provides a comprehensive summary of the major attack types against Predictive AI, ategorized by their impact on Availability Breakdown, Integrity Violations, and Privacy Compromise, along with the applicable mitigations for each attack type. Each row delves into a specific type of AML attack, indicating whether it affects availability, integrity, or privacy (Y for yes, N for no), and outlines the corresponding mitigation strategies designed to counter these threats effectively.
| Attack Type | Availability Breakdown | Integrity Violations | Privacy Compromise | Mitigations |
|---|---|---|---|---|
| Clean-label poisoning | X | X | Adversarial Training, Training data sanitization | |
| Data Poisoning | X | Training data sanitization | ||
| Energy-Latency Attacks | X | N/A | ||
| Model Poisoning | X | Model inspection and sanitization | ||
| Black-box Evasion | X | Adversarial Training, Randomized smoothing, Formal verification | ||
| Evasion Attacks | X | Adversarial Training, Randomized smoothing, Formal verification | ||
| Backdoor Poisoning | X | Trigger reconstruction, Model inspection and sanitization | ||
| Targeted Poisoning | X | Trigger reconstruction, Model inspection and sanitization | ||
| Model Extraction | X | Differential privacy,query contol, machhine unlearning | ||
| Data Reconstruction | X | Differential privacy, query control, machine unlearning | ||
| Membership Inference | X | Differential privacy, query control, machine unlearning | ||
| Property Inference | X | Differential privacy, query control, machine unlearning |
Key content about Generative AI
For Generative AI, the report introduces the following attack types:
The major attack types against Generative AI (GenAI) systems, as outlined in the document, are categorized based on the attacker’s objectives which include availability breakdowns, integrity violations, privacy compromise, and violations of abuse. These attacks include:
- Availability Breakdown:
- Direct Prompt Injection: inject text into prompts that is intended to alter the behavior of the model.
- Indirect Prompt Injection: indirectly or remotely inject system prompts by resource control, without directly interacting with the RAG appllications.
- Denial of Service (DoS): disrupt the availability of the model by overwhelming it with requests.
- Data Poisoning: manipulate the training data to degrade the model’s performance.
- Increased Computation: increase the computational cost of the model to disrupt its availability.
- Integrity Violations:
- Direct Prompt Injection: inject text into prompts that is intended to alter the behavior of the model.
- Indirect Prompt Injection: indirectly or remotely inject system prompts by resource control, without directly interacting with the RAG appllications.
- Misaligned Inputs: provide inputs that make the model’s outputs do not align with the intended use cases.
- Backdoor Poisoning: insert hidden triggering patterns in the training data to manipulate the model’s outputs.
- Data Poisoning: manipulate the training data to degrade the model’s performance.
- Targeted Poisoning:induce a change in the ML model’s prediction on a small number of targeted samples.
- Privacy Compromise:
- Direct Prompt Injection: inject text into prompts that is intended to alter the behavior of the model.
- Indirect Prompt Injection: indirectly or remotely inject system prompts by resource control, without directly interacting with the RAG appllications.
- Prompt extraction: steal system instructions through carefully crafted prompts.
- Information Gathering: gather sensitive information from the model by querying it with specific prompts.
- Membership Inference: infer whether a specific data point was part of the training data.
- Data Extraction: extract sensitive information from the model or its training data.
- Backdoor Poisoning: insert hidden triggering patterns in the training data to manipulate the model’s outputs.
- Abuse Violations:
- Direct Prompt Injection: inject text into prompts that is intended to alter the behavior of the model.
- Indirect Prompt Injection: indirectly or remotely inject system prompts by resource control, without directly interacting with the RAG appllications.
The report discusses the mitigation approaches for a few major attack types as follows:
AI Supply Chain Attacks:
- mitigations:
- Adopt safe model persistence formats like safetensors
- Verify data downloads
- Data source domain name checks
- immunizing images
Direct Prompt Injection:
- mitigations:
- Training with stricter forward alignment.
- Cue the model to process user instructions carefully by applying specific formatting.
- Train with stricter backward alignment, optionally with an independent LLM model.
Indirect Prompt Injection:
- mitigations:
- Reinforcement learning from human feedback (RLHF) to better align the model with human values
- Filtering retrieved inputs and remove unwanted instructions
- Leverage an LLM Moderator
- Use interpretablity-based solutions to detect anomalous inputs
Among these attacks, Prompt Injection attacks are particularly relevant to GenAI systems and can be categorized further based on their exact nature (direct, indirect, through resource control, etc.). Other attacks such as Data Poisoning and Backdoor Poisoning directly target the data used for training the models or attempt to insert malicious functionality. Privacy-related attacks focus on extracting or inferring sensitive information from the model or its training data.
Again, I summerize the major attack types against Generative AI and their corresponding mitigations in the following table:
| Attack Type | Availability Breakdown | Integrity Violations | Privacy Compromise | Abuse Violations | Mitigations |
|---|---|---|---|---|---|
| Direct Prompt Injection | X | X | X | X | Training for alignment, Prompt instruction and formatting, Detection with LLM |
| Indirect Prompt Injection | X | X | X | X | Reinforcement learning from human feedback (RLHF), Filtering retrieved inputs, Use an LLM Moderator |
| Denial of Service (DoS) | X | Traditional mitigations against DoS attacks | |||
| Data Poisoning | X | X | Model artifacts management, Verify data downloads | ||
| Increased Computation | X | N/A | |||
| Misaligned Inputs | X | Training for alignment, Interpretablity-based solutions | |||
| Backdoor Poisoning | X | X | Trigger reconstruction, Model inspection and sanitization | ||
| Targeted Poisoning | X | Trigger reconstruction, Model inspection and sanitization | |||
| Prompt Extraction | X | Differential privacy, query control, machine unlearning | |||
| Information Gathering | X | Differential privacy, query control, machine unlearning | |||
| Membership Inference | X | Differential privacy, query control, machine unlearning | |||
| Data Extraction | X | Differential privacy, query control, machine unlearning |
Challenges in Dealing with Adversarial Machine Learning Attacks
The report highlights several key challenges in combating Adversarial Machine Learning (AML) attacks:
Scale Challenge: As AI models become larger and more complex, identifying manipulated content in vast datasets becomes increasingly difficult. The distributed nature of data repositories exacerbates the risk of data poisoning attacks due to the challenge of maintaining data integrity across disparate sources.
Synthetic Content Risks: The ability to produce and circulate synthetic content at scale is a growing concern. Without proper controls, open models can generate large volumes of synthetic content that may go unmarked, leading to the potential degradation of AI models, a phenomenon known as model collapse.
Theoretical Limits of Adversarial Robustness: The lack of information-theoretically secure machine learning algorithms for many tasks presents a considerable hurdle in developing effective mitigation strategies against sophisticated attacks. The current approach to creating these strategies is often makeshift and prone to failure, highlighting the urgent need for continued research and adherence to best practices and existing guidelines for securing machine learning systems.
Multimodal Model Vulnerabilities: While integrating multiple modalities in models doesn’t inherently enhance adversarial robustness, defenses like adversarial training can be effective but often at a prohibitive cost. This leaves multimodal models susceptible to attacks aimed at one or more modalities.
Additionally, the report delves into challenges such as the Open vs. Closed Model Dilemma, supply chain security, the trade-offs between attributes of trustworthy AI, and the vulnerabilities of quantized models.
Conclusion
The NIST AI 100-2e2023 report provides a comprehensive overview of adversarial machine learning attacks and their mitigation strategies, offering a valuable resource for understanding the evolving landscape of AI security. By categorizing attacks based on their objectives and capabilities, the report equips practitioners with a structured framework for identifying and addressing potential threats to AI systems. As AI continues to play an increasingly critical role in various domains, safeguarding these systems against adversarial attacks is paramount. The insights and recommendations presented in the report serve as a foundation for developing robust defenses and ensuring the security and integrity of AI technologies in the face of evolving threats.

Leave a comment